Lip-Interact: Improving Mobile Device Interaction with Silent Speech Commands
We present Lip-Interact, an interaction technique that allows users to issue commands on their smartphone through silent speech. Lip-Interact repurposes the front camera to capture the user’s mouth movements and recognize the issued commands with an end-to-end deep learning model. Our system supports 44 commands for accessing both system-level functionalities (launching apps, changing system settings, and handling pop-up windows) and application-level functionalities. We demonstrate that Lip-Interact can help users access functionality efficiently in one step, enable one-handed input, and assist touch to make interactions more fluent.
Background and Opportunity
Today’s smartphones enable a wide range of functionalities. At present, most of the devices rely on touch as the primary input approach. However, simply tapping on the screen with a fingertip lacks expressivity. Given the limited screen size and hierarchical UI layouts, reaching a desired item often requires multiple steps of sliding and clicking. Voice input is an alternative channel that offers rich expressivity and enables always-available interaction. However, voice recognition can be easily affected by ambient noise and people do not use it in many circumstances due to the privacy concerns.
In this paper, we introduce Lip-Interact, which enables users to access functionality on the smartphone by issuing silent speech commands. For example, to take a selfie, a user can simply mouth the verbal command "open camera" to directly launch the app in one step instead of searching for it manually, and then mouth "capture" to trigger the shutter button rather than reaching it with the unstable thumb and causing the picture to blur. Also, a user can issue commands such as: "home", "back", "screenshot", "flashlight" and so on to easily control the device’s settings.
The goal of Lip-Interact is to provide a simple, yet powerful approach to issuing commands on the smartphone. Compared with general audible voice input, the main difference is that Lip-Interact commands are silent and recognized by the camera. Therefore, the interaction is immune to ambient noise and largely alleviates the issues surrounding personal privacy and social norms in public environment.
Design for Lip-Interact
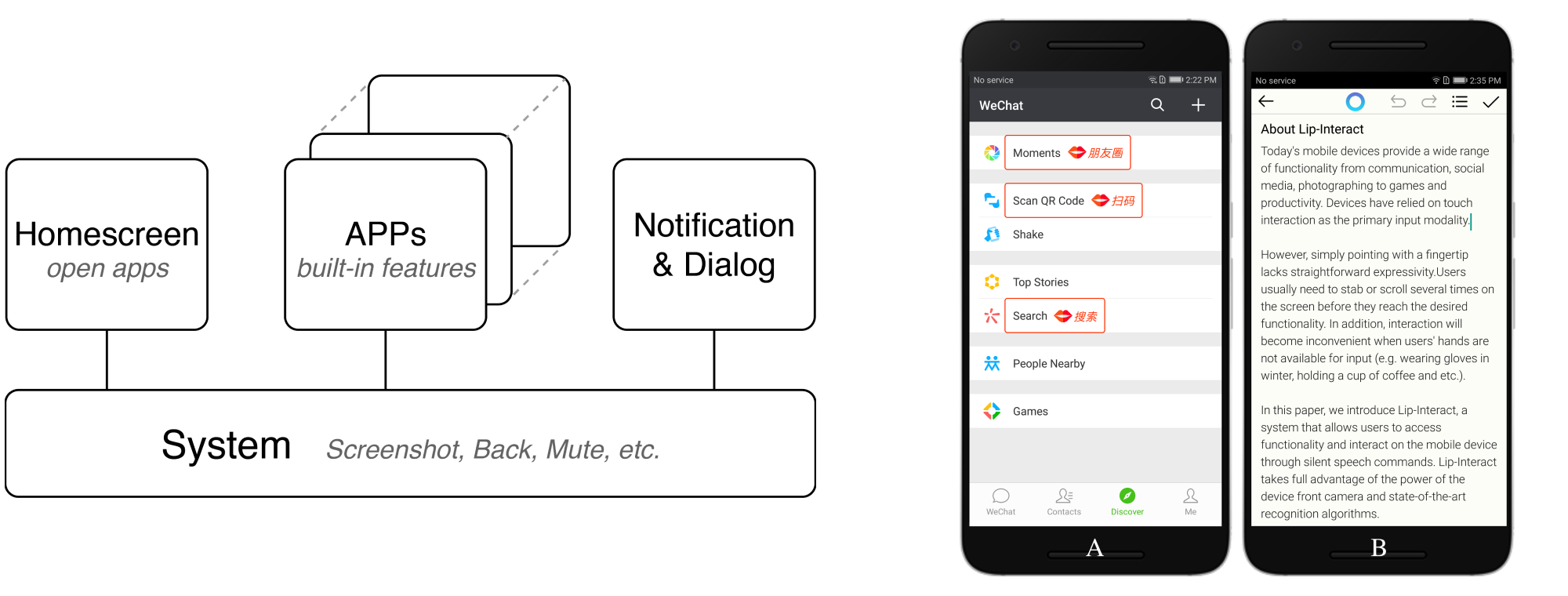
Compatible with Existing Touch Interaction
The goal of Lip-Interact is to offer users an alternative based on their current cognitive and motor conditions when touch is inferior. Lip-Interact can also work together with touch to enable a more efficient and fluent user input experience. For example, a user may prefer to type with fingers while using Lip-Interact for fast text editing (e.g. bold, highlight, undo, etc).
High Level of Recognition Accuracy
Concise and Differentiable Commands. Lip-Interact only considers short and visually distinguishable commands rather than long sentences such as those in a conversational system.
Properly Exaggerating Lip Movements. Users are instructed to issue commands in a more "standard" way than when they are casually talking by exaggerating theirlip movements. Users only need to mouth the command by thinking that their lip movement can present each syllable clearly.
Context-Aware Functionality Support
Lip-Interact is context aware: covering different aspects of functionality when using different applications. The system identifies the current state and uses the corresponding model to recognize users’ input.
User Learning and System Feedback
With Lip-Interact on a smartphone, the user should be clearly informed about commands that are currently available. When a feature is exposed to a user for the first time, a floating window is displayed around the icon with its command words on it. When the system detects that the user is issuing commands, a real-time visual indicator appears at the top of the screen.
System Implementation
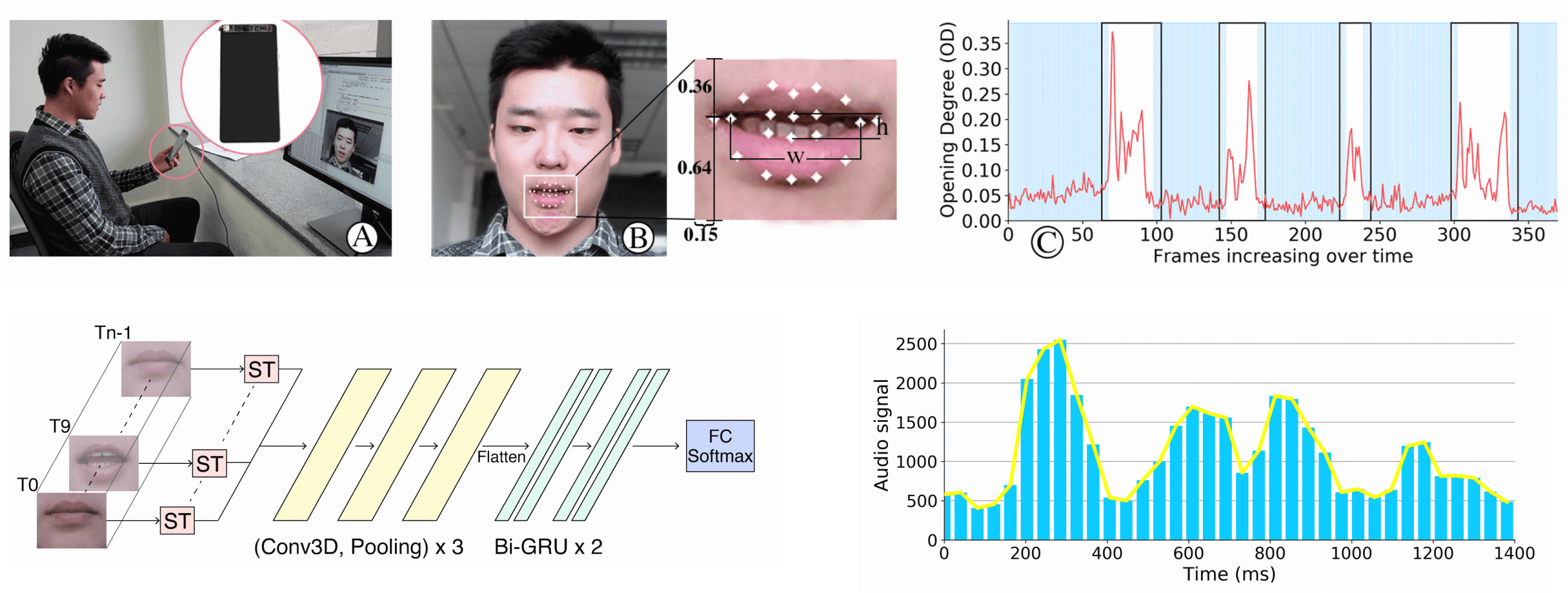
Segmenting Mouth Sequence of Silent Speaking
The frames from the front camera are processed with a face detector to identify the facial landmarks. The Opening Degree of the mouth is measured. To segment the command issuing sequence, an online sliding window algorithm is used to to detect and transfer between the following four states: begin speaking, continue speaking, stop speaking and other. Within each sliding window, seven statistical features of OD are calculated and handled by a machine learning model to to decide whether or not to remain in the current state or move to the next state. The RGB channels of the mouth images over the speaking interval T are normalized to have zero mean and unit variance.
End-to-End Deep-Learning Command Recognition
Spatial Transformer. The architecture starts with a Spatial Transformer network on each input frame. The Spatial Transformer is a learnable module which has the ability to spatially transform feature maps, allowing the model to learn invariance to rotation. Our spatial transformer module uses bilinear sampling and a 16-point thin plate spline transformation with a regular grid of control points as the transformation function to solve relative mouth positioning towards the camera.
Representation Learning and Dynamic Modelling. The output frames of each Spatial Transformer module are concatenated along the time dimension. The features extracted by the convolutional nets are then flattened and passed into two bidirectional Gated Recurrent Units (GRU) for the modelling of dynamics. Finally, the output at the last time-step of the second GRU is followed by a fully connected layer with a softmax function to predict the lip-command class.
Post-Vocal Check
After the recognizer returns the result, a vocal check is applied to distinguish Lip-Interact from users’ normal speaking. For example, talking to other people while using the device will also result in mouth movement but should not be detected as issuing a Lip-Interact command. We first apply a band-pass filter on the audio signal to remove part of the background noise, and then calculate the peaks (syllables) of the signal. If the number of the syllables does match the command words of the recognition result, it is decided that the user is not using Lip-Interact.
User Learning and System Feedback
With Lip-Interact on a smartphone, the user should be clearly informed about commands that are currently available. When a feature is exposed to a user for the first time, a floating window is displayed around the icon with its command words on it. When the system detects that the user is issuing commands, a real-time visual indicator appears at the top of the screen.
Experiment
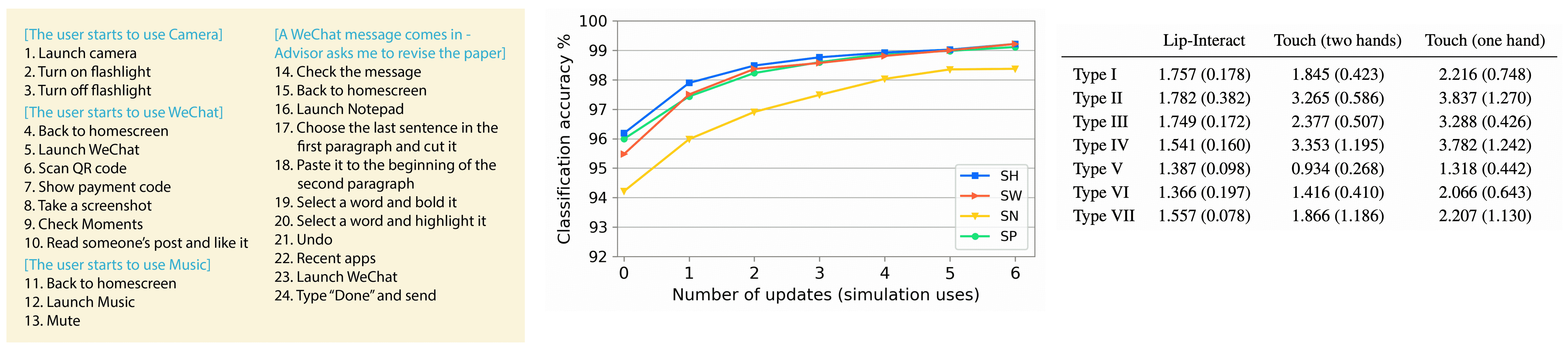
On a limited set of mobile interactions, the commands issued by users through silent speech can be distinguished accurately by vision-only methods. Our deep learning model has sufficient generalization ability for new users with a recognition accuracy of over 95%. The model is expected to have a strong learning ability in real-world scenarios, since smartphones are usually used by only a single user.
For each interaction type, the input time is significantly affected by input condition. On average, participants spend less time with Lip-Interact on all interaction types except for Type V. Lip-Interact increases input speed the most for Type II, Type III and Type IV, with an improvement of 26.42% ∼ 54.05% compared to touch with two hands and 46.81% ∼ 59.25% compared to touch with one hand. These tasks generally require multiple steps of touch operations to complete.