One-Dimensional Handwriting: Inputting Letters and Words on Smart Glasses
We present 1D Handwriting, a unistroke gesture technique enabling text entry on a one-dimensional interface. The challenge is to map two-dimensional handwriting to a reduced one-dimensional space, while achieving a balance between memorability and performance efficiency. After an iterative design, we finally derive a set of ambiguous twolength unistroke gestures, each mapping to 1-4 letters. To input words, we design a Bayesian algorithm that takes into account the probability of gestures and the language model. To input letters, we design a pause gesture allowing users to switch into letter selection mode seamlessly. With extensive training, text entry rate can reach 19.6 WPM. Users’ subjective feedback indicates 1D Handwriting is easy to learn and efficient to use.
Background and Opportunity
Nowadays, many new smart personal devices are emerging. Such devices typically have a constrained input interface due to the limited size of the form factor. Consequently, text entry is difficult on these devices, which prohibits their broader use. We focus on one-dimensional text entry for devices that have only one-dimensional input signals, or the input capacity on one dimension is much greater than that on the other. Examples include the touchable spectacle frame of a smart glass (e.g. Google Glass), the edge of a side screen of a smart phone (e.g. GALAXY Note Edge), and a smart wristband.
Iterative Design
The goal was to gain an understanding about user acceptance of 1D Handwriting gestures as well as the input capacity of Google Glass. To achieve this, we first derived a set of 1D Handwriting stroke gestures, and then asked individual participant to assess their intuitiveness by performing them on Google Glass. Based on the subjective and objective results, we agreed on the design guidelines for the final handwriting gestures, and revised our design.
Phase 1 —Initial Design of Handwriting Gestures
In our first trial, we adopted a user-participatory approach. We recruited eight participants and asked them to design a set of one-dimensional gestures for Google Glass. The guideline was to design a 1D Handwriting stroke gesture for each letter to best mimic their two-dimensional counterparts. For some letters, the design was easy and intuitive. For example, the handwriting stroke gesture of “w” should be a four-stroke gesture “back—forward—back—forward”. However, for others it was not an easy task since several letters were similar, if not identical, when projected into a reduced one-dimensional space. In such cases, we designed strokes with more details (e.g. adding a short stroke at the end to distinguish “q” from “y”), or use a dot to distinguish them, such as “b” and “k”. The design of handwriting gestures employed strokes of three levels of lengths (i.e. short, medium and long) and a dot.
Phase 2 — Data Collection and User assessment
Participants were asked to memorize the handwriting gesture set and were instructed to perform these gestures at their comfortable speed.
Memorability. Although the overall handwriting strokes esembled two-dimensional handwriting, the small adjustments (i.e. short strokes and dots) made it difficult for users to remember actual strokes. Participants had to remember the strokes by heart, which was not easy given the limited time for learning the stroke gestures. Moreover, it was found that individual participants should have discrepant models for interpreting the handwriting stroke gestures.
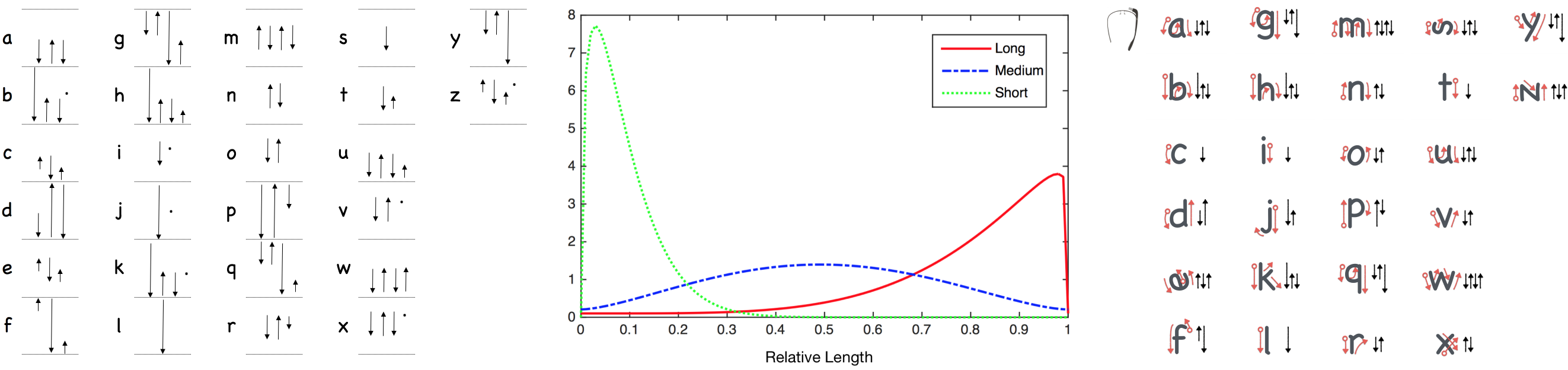
Input accuracy. It was difficult for participants to distinguish between three levels of stroke length. Above figure shows the distribution of short, medium and long sub-strokes. There was much overlap between the three-level lengths of sub-strokes. In addition, participants occasionally performed unintended hooks at the beginning or end of a stroke, making short strokes even more difficult to recognize by algorithm. Therefore, we intend to drop short strokes from our design and be in favor of a two-level design of stroke length (medium and long).
Phase 3 — Final Design of the Handwriting Gestures
Based on the above results, we decided to remove the requirement of one-to-one mapping of gestures to letters, which posed a major challenge for designing handwriting stroke gestures with good memorability and usage efficiency. Instead, we allowed a handwriting stroke gesture to represent more than one letter if necessary. This decision was inspired by an ambiguous keyboard that was also for resolving the limitation of input resources (e.g. a keypad with a small number of buttons). Based on the information gathered during the initial design of the handwriting stroke gestures, we formed the following guidelines for the gesture design.
- Mimic traditional handwriting: 1D Handwriting stroke gestures should be easy to learn. By mimicking traditional handwriting, the obtained strokes should be easy to be remembered.
- Minimize levels of stroke lengths: In order to perform stroke gestures accurately and efficiently.
- Minimize number of sub-strokes per letter: In order to perform stroke gestures efficiently.
- Single stroke input: In order to perform stroke gestures efficiently.
Above figure illustrates the final stroke design for each letter. The design was based on glyphs of lower-case letters since most of these are performed with a single stroke. In total, we designed 13 stroke gestures, which were mapped to the 26 letters of the alphabet.
The Technique
Gesture Recognition
The purpose is to estimate a posteriori probability of a handwriting stroke input (\(s\)) given a stroke template (\(t\)), rather than to discretely classify it into a specific template. Note that according to our design, a stroke template may represent more than one letter. We can then use the estimated result to produce letter-level input and dictionary-based word-level input.
We assume the estimation of individual normalized sub- strokes to be independent from each other. We have
$$ P(s \mid t) = \prod_{i=1}^{n} P(s_{i} \mid t_{i}) $$where the probability density function of \( P(s_{i} \mid t_{i}) \) is given according to the result of the previous user study.
Predicting Target Words
A user inputs a sequence of strokes \( I = s_{1} \ldots s_{n} \) to input one word \( w \) from a vocabulary \( V \). The word has n letters, that is, \( w = l_{1} \ldots l_{n} \). The algorithm predicts a number of likely words based on the probability of gesture input and language model. The posterior probability of \( I \) given a word \( w \) can be computed as follows:
We assume the estimation of individual normalized sub- strokes to be independent from each other. We have
$$ P(w \mid I) = P(w, I) \cdot P(I) $$We have no knowledge of \( I \) and assume each letter input is independent from each other, we can compute
$$ \begin{eqnarray} P(w, I) & = & P(w) \cdot P(I/w) \\ & = & P(w) \cdot \prod_{i=1}^{n} P(s_{i} \mid l_{i}) \\ & = & P(w) \cdot \prod_{i=1}^{n} P(g_{i} \mid t(l_{i})) \end{eqnarray} $$where \( t(l_{i}) \) is the stroke template of letter \( l_{i} \). If no matches are found, the algorithm attempts to make auto-completions by computing the probability of words that have more letters than the input sequence. All predicted words are sorted, according to their probability, and presented to the user in descending order.
Interaction Design
This figure shows the interface of the 1D Handwriting system on Google Glass that users can see on the virtual screen. It is divided into three regions. The Text region (the middle row) displays the input text. The Letter region (the top row) displays the recognized letters. The Word region (the bottom row) displays the five most likely words.

Input a word. Users input words by performing the respective stroke gestures of each letter in sequence. Words that most likely correspond to the current input (at most five) are shown in the Word region. Users can directly select the most likely word out of them by tapping the touchpad with two fingers, or select the other words by performing a two-finger movement to select the desired word, followed by a two-finger tap to confirm. When a word is selected, the system automatically appends a space to the end.
Input a letter. The system is set by default to word input mode. In order to input a letter, users have to place their finger on the touchpad for 300ms (empirically determined) after performing a stroke. At that point, the system will switch to letter input mode (with the frame of the Letter region highlighted) allowing users to move their finger on the touchpad to select letters. Lifting the finger will confirm the selection. This design offers a seamless one-finger gesture for inputting letters.
Delete a letter. Deletion of a letter is performed with a swipe-up gesture or by clicking the camera button.